Working Women and Caste in India: A Study of Social Disadvantage using Feature Attribution

Abstract
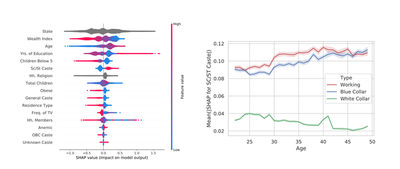
Women belonging to the socially disadvantaged caste-groups in India have historically been engaged in labour-intensive, blue-collar work. We study whether there has been any change in the ability to predict a woman’s work-status and work-type based on her caste by interpreting machine learning models using feature attribution. We find that caste is now a less important determinant of work for the younger generation of women compared to the older generation. Moreover, younger women from disadvantaged castes are now more likely to be working in white-collar jobs.
The story behind the project is interesting: Kuhu, my elder sister, had been reading about how economists have been using machine learning to do interesting things. In particular, she was fascinated by Bertrand and Kamenica’s work on how the US population’s cultural distance might be changing, and this tutorial/paper by Mullainathan and Spiess. During the summer holidays of 2018, she asked me to teach her the basics of machine learning and Python programming. We started brainstorming ideas while we were at it…
We came up with an approch similar to B and K, applying feature attribution to study the generational imact of caste on women’s labour force participation in India. We used Random Forest models on a large nationally-representative dataset (NFHS-4) to predict whether a woman was employed in white-collar/blue-collar jobs or unemployed. Next, we interpretted the trained models using the SHAP feature attribution framework.
Working remotely between New Delhi and Singapore, we submitted our work to the AI for Social Good Workshop at ICLR 2019 without too many expectations. Amazingly, we got accepted as a poster! We were officially co-authors now!
Kuhu travelled to New Orleans to present our poster and got a lot of useful feedback. Being junior researchers, we took ICLR (and my subsequent trip to NeurIPS) as an opportunity to speak to established researchers and students working in the intersection of social policy and machine learning. These conversations helped us understand the limitations of our work, leading us to make an addendum in the arXiv report with additional experiments on the robustness of our findings.