Learning the Travelling Salesperson Problem Requires Rethinking Generalization
Abstract
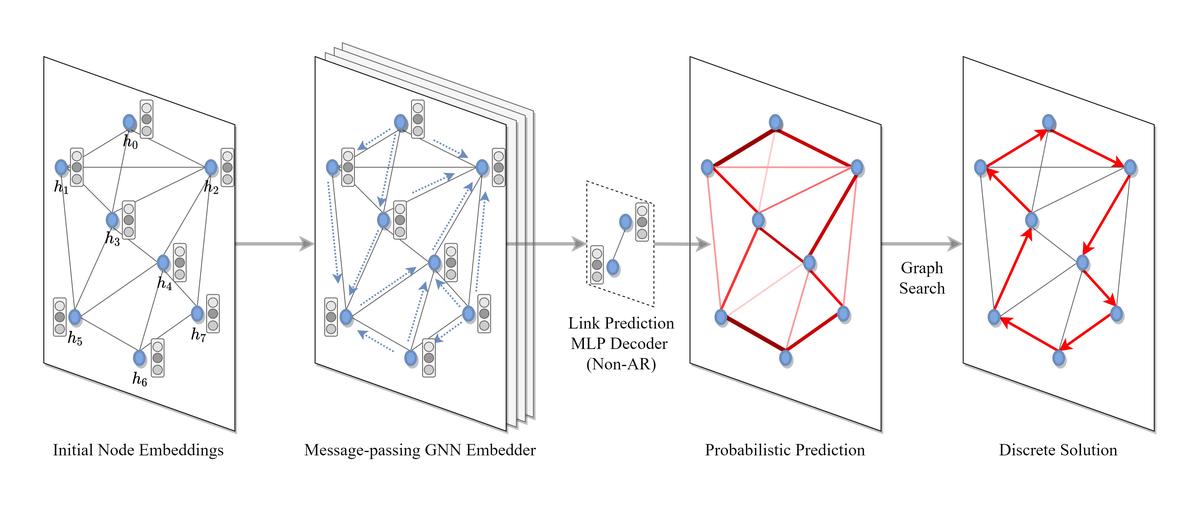
End-to-end training of neural network solvers for graph combinatorial optimization problems such as the Travelling Salesperson Problem (TSP) have seen a surge of interest recently, but remain intractable and inefficient beyond graphs with few hundreds of nodes. While state-of-the-art learning-driven approaches for TSP perform closely to classical solvers when trained on trivially small sizes, they are unable to generalize the learnt policy to larger instances at practical scales. This work presents an end-to-end neural combinatorial optimization pipeline that unifies several recent papers in order to identify the inductive biases, model architectures and learning algorithms that promote generalization to instances larger than those seen in training. Our controlled experiments provide the first principled investigation into such zero-shot generalization, revealing that extrapolating beyond training data requires rethinking the neural combinatorial optimization pipeline, from network layers and learning paradigms to evaluation protocols. Additionally, we analyze recent advances in deep learning for routing problems through the lens of our pipeline and provide new directions to stimulate future research.