Abstract
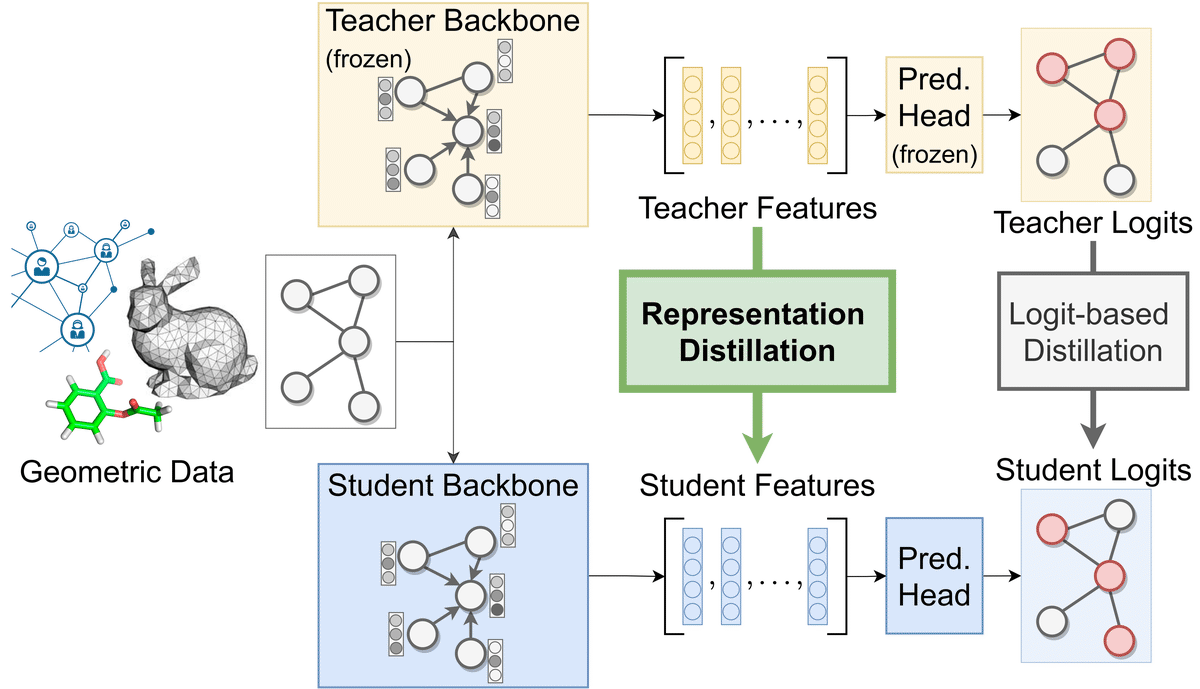
Knowledge distillation is a learning paradigm for boosting resource-efficient graph neural networks (GNNs) using more expressive yet cumbersome teacher models. Past work on distillation for GNNs proposed the Local Structure Preserving loss (LSP), which matches local structural relationships defined over edges across the student and teacher’s node embeddings. This paper studies whether preserving the global topology of how the teacher embeds graph data can be a more effective distillation objective for GNNs, as real-world graphs often contain latent interactions and noisy edges. We propose Graph Contrastive Representation Distillation (G-CRD), which uses contrastive learning to implicitly preserve global topology by aligning the student node embeddings to those of the teacher in a shared representation space. Additionally, we introduce an expanded set of benchmarks on large-scale real-world datasets where the performance gap between teacher and student GNNs is non-negligible. Experiments across 4 datasets and 14 heterogeneous GNN architectures show that G-CRD consistently boosts the performance and robustness of lightweight GNNs, outperforming LSP (and a global structure preserving variant of LSP) as well as baselines from 2D computer vision. An analysis of the representational similarity among teacher and student embedding spaces reveals that G-CRD balances preserving local and global relationships, while structure preserving approaches are best at preserving one or the other.